

自2022年11月30日ChatGPT惊艳亮相以来,AI大模型领域掀起了前所未有的热潮。国内大模型紧随其后,并在短短一年间取得了显著突破。从准备期的迅速响应,到成长期的稳步增长,再到爆发期的百模大战,国内大模型领域正以前所未有的速度发展。
尽管如此,但与全球领先者GPT4-Turbo相比,国内同行仍存在明显差距。
根据权威的中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)的最新报告,GPT4-Turbo以惊人的89.79分总成绩荣登榜首,其卓越性能遥遥领先,不仅超过了国内所有的大型语言模型,也显著超越了国外一系列具有代表性的大模型。紧随其后的是国内的最佳模型文心一言4.0,它以74.02分的成绩紧随其后,尽管表现不俗,但与GPT4-Turbo相比,仍存在15.77分的显著差距。这一结果再次证明了GPT4-Turbo在中文语言理解领域的卓越实力与领先地位。
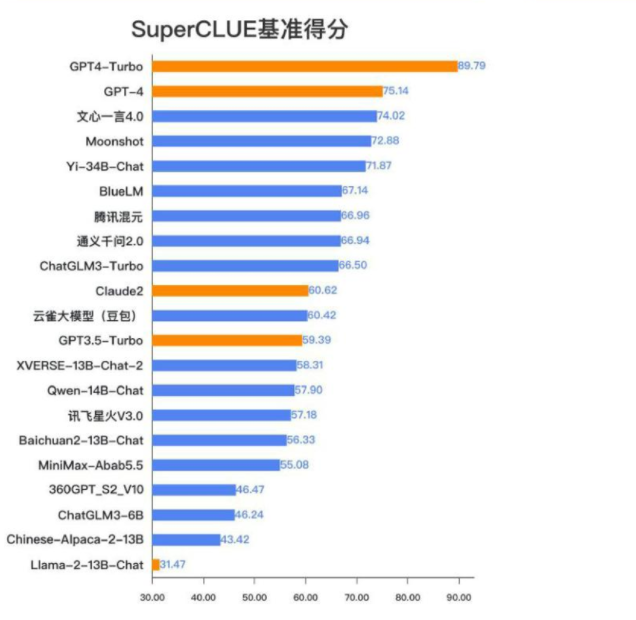
文中图表资料来源于2023年发布的
《中文大模型基准测评报告》
一、评分标准
SuperCLUE,作为CLUE基准的进阶版,致力于全面评估大模型在中文语言理解领域的综合能力。其评分标准从多维度和多视角出发,包括多轮开放问题(SuperCLUE-OPEN)和三大能力客观题(SuperCLUE-OPT)。
评测集共包含4265道题目,其中1052道为OPEN类多轮简答题,用于测试模型在连续性和深度理解上的能力;另外3213道为OPT类客观选择题,旨在评估模型在逻辑推理、信息抽取和分类等技能方面的表现。
这些题目紧密贴合学术、产业及用户端的实际应用场景,构建了一个全面、多层次的综合性测评体系。这一体系不仅确保了测评的准确性和客观性,更为大模型的研发者和使用者提供了有价值的参考,进一步推动了大模型技术的不断发展。
二、大模型对战胜率分布图
在SuperCLUE-OPEN多轮开放式问题基准测试中,GPT4-Turbo以49.34%的胜率大幅领先于其他模型。其和率也高达48.19%,败率仅为2.4%。这一数据充分证明了GPT4-Turbo在各项能力上的全面优势。
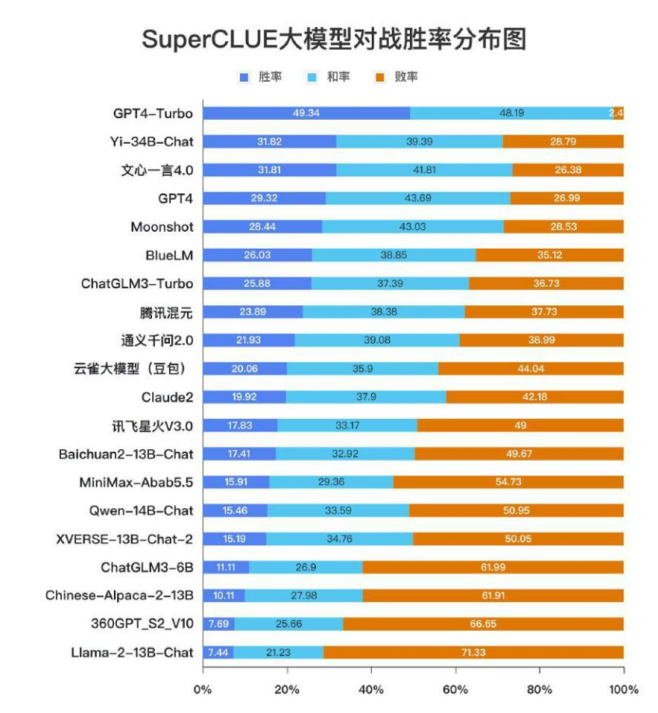
文中图表资料来源于2023年发布的
《中文大模型基准测评报告》
三、四大维度测评结果及示例
从图表中可以看出,在语言理解与生成方面,GPT-4 Turbo能够更准确捕捉用户意图,生成流畅自然的文本回复。
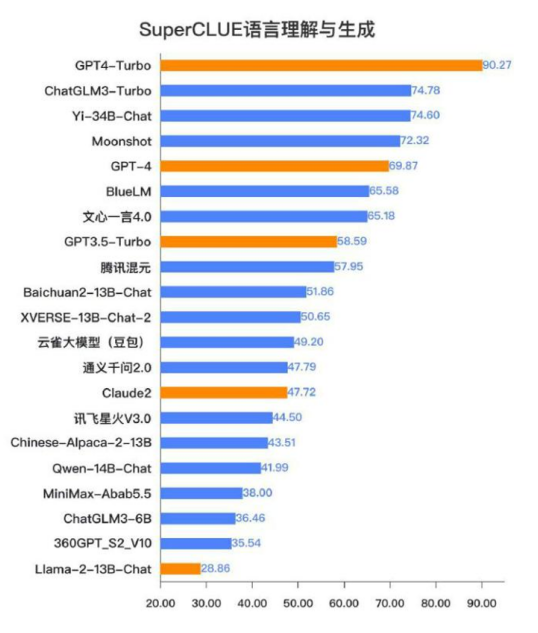
文中图表资料来源于2023年发布的
《中文大模型基准测评报告》
在专业技能与知识方面,它能够更好解答各类专业问题,提供准确的信息和建议。
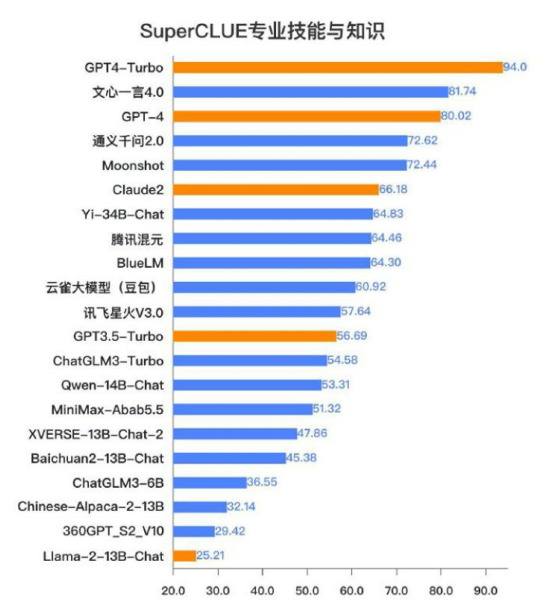
文中图表资料来源于2023年发布的
《中文大模型基准测评报告》
工具使用方面,GPT-4 Turbo能够更高效完成包括代码编写和图像处理在内的复杂任务。
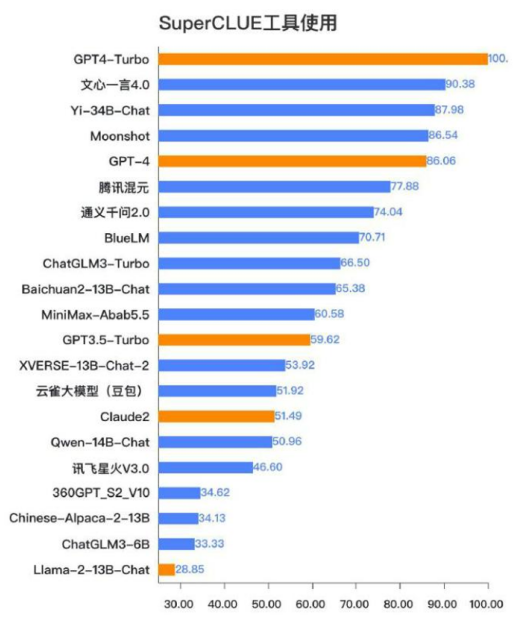
文中图表资料来源于2023年发布的
《中文大模型基准测评报告》
综上所述,GPT-4 Turbo凭借其卓越的语言理解与生成能力、广泛的专业知识、强大的工具使用功能以及良好的传统安全适应性,成为智能问答领域的佼佼者。其出色表现不仅为用户带来了便捷高效的智能服务体验,也为行业发展树立了新的标杆。
四、聚会问AI智能问答上线
尽管ChatGPT以其卓越的性能和智能问答能力在全球范围内广受赞誉,但国内用户在使用时仍面临一个明显的痛点——访问限制。国内用户因为不能直接访问ChatGPT而感到不便。并且注册一个ChatGPT Plus版本存在更多的限制。
为了解决这一问题,聚加互动经过精心研发和打磨,推出全新的【聚会问AI智能问答】。这款工具无缝对接了ChatGPT Turbo的能力,更在易用性上进行了全面优化和提升。
功能卓越:
【聚会问AI智能问答】不仅拥有ChatGPT Plus强大的问答能力;同时,它还具备OpenAI DALL·E 3.0图片生成功能。
易用便捷:
用户无需翻墙、无需海外信用卡,在国内即可轻松访问和使用。无论是手机端还是电脑端,只需点击链接,即可进入简洁明了的界面。
总之,【聚会问AI智能问答】解决了用户在使用ChatGPT时面临的访问限制痛点,让更多人能够轻松享受AI带来的智能体验。